Beta release journal
2025-12-16

Repo 地址:
GitHub - shuxueshuxue/ink-and-memory: A responsive AI notebook that helps you record and explore your life.
Demo 地址:
ink-and-memory
我们是 ink&memory (初期项目名为 Echo) 团队,我们致力于构建一个有"灵性"的 AI 日记本,帮助人们更好地记录生活、理解自我。
Beta 阶段我们做了什么:
1.1 完善了 CI/CD 流程,实现了自动打包 docker 镜像并于服务器部署,以及自动的冒烟测试
1.2 解决了一大批 paper cut 问题,提高了各个页面的加载速度(尤其是 timeline 页面的动态加载),优化了整体 UI 的排版、流畅度:例如 deck 页面改用了点击卡组来弹出详细信息的方式,工具栏有工具的解释,更全面的中英文切换等。
1.3 化繁为简,删减掉了之前加入的好友系统,决定专注于交互核心。经过反复测试,我们对 agent 在实际运行中出现的问题进行了详细的分类,针对性地优化了默认 agent 卡组。
1.4 可用性大幅提升。虽然功能不多,产品已经完整。我们总结了目前情感计算领域内相关的研究,有了基本的创新模型和算法的思路,之后我们会继续把核心写作页面的交互体验优化到极致。
1.5 在社交媒体上进行了一定的宣传。但目前没有深入目标用户群体,仅依赖自来水流量,浏览量较少,点进网站进行试用的用户往往是对产品比较喜欢的(因为只有对这个题材感兴趣才会去试用)。我们尚未有足够的时间来用户留存率的测试。下一步将是设计如何在目标群体中进行宣传。
Need
对于需求的验证:通过对近 20 位用户使用体验的访谈,我们发现用户对于“写日记时获得回应”这件事存在明确的需求,但是对其具体的实现方式有不同的意见,具体而言
- 对 AI 的干预方式各有不同的看法:有的倾向于实时反馈,有的倾向于自己掌控,不被中途打扰
- 对 AI 回复质量的要求非常高,这类用户往往是并没写日记刚需的,因此需要产品给他更强的动机去改变习惯
- 希望 AI 能深入了解自己,能有更多的反馈
Approach
我们已经全部实现产品的基础功能,包括写作、时间线、深度回顾、智能体定制四个方面。
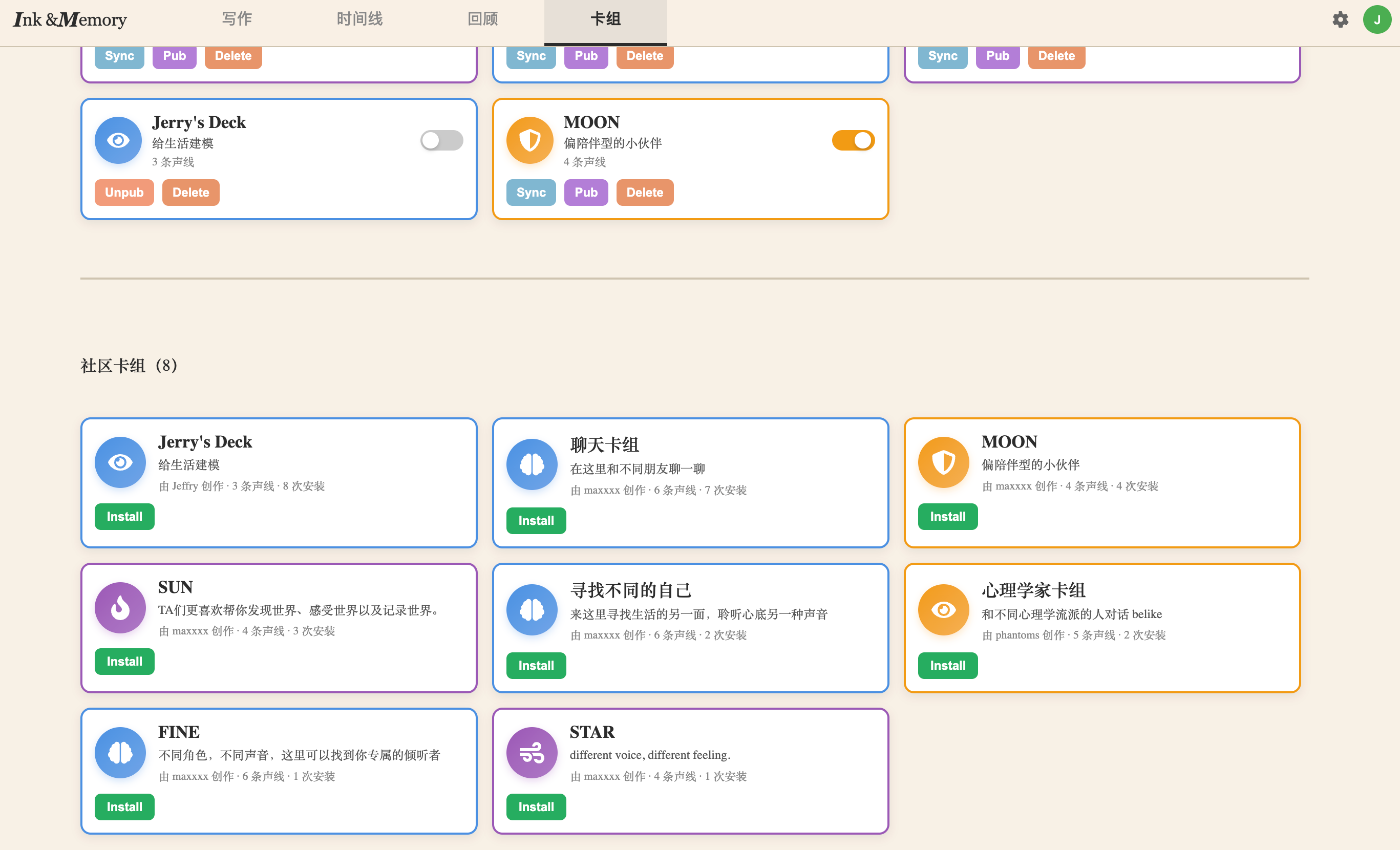
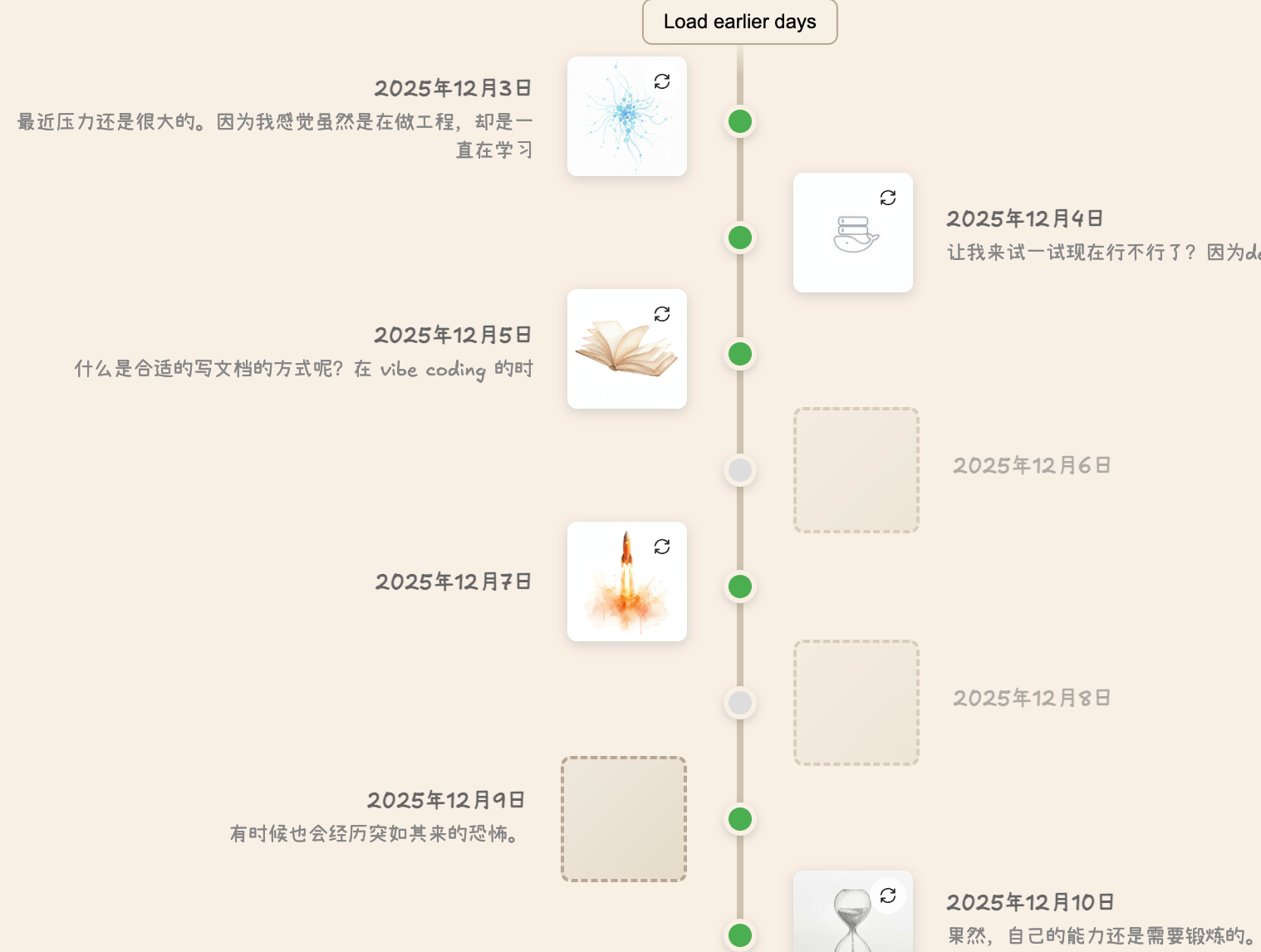
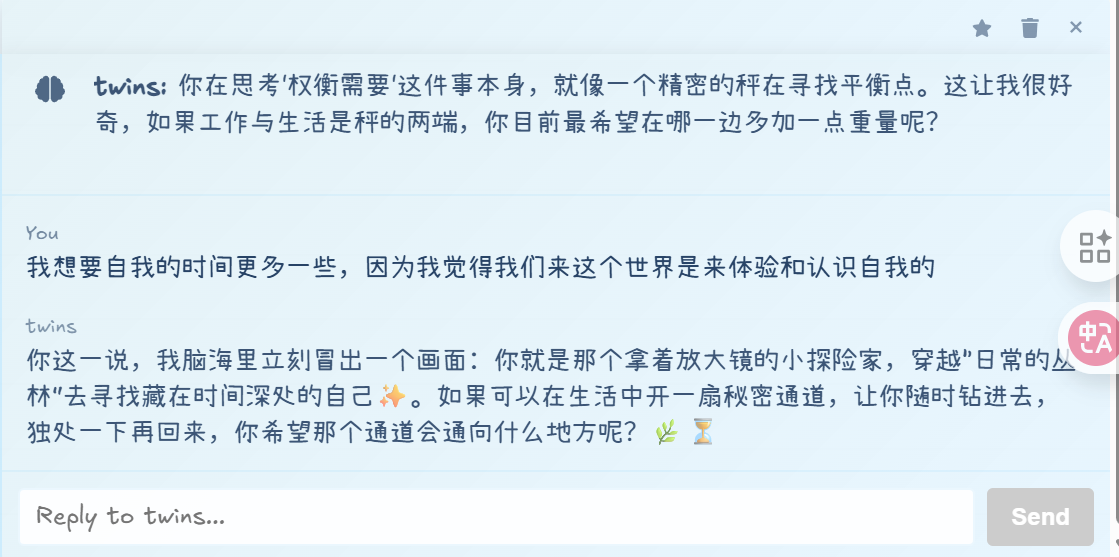
Benefit
通过前期的测试,我们已经确定用户偏好,确实是喜欢多 Agent 的互动而不是单个 Agent(很快会无聊,而且众口难调)。这是我们的核心优势所在。
Competition
我们的竞争对手分为两种类型,传统日记产品和 AI+日记产品。
对于传统日记产品,他们往往以“写了多少字、多少篇日记”来给用户长期反馈,但我们相信一个“懂你的 AI”给你的“年度表白”能带来的情绪价值远大于一个“今年写了多少篇日记”的数字。
对于AI+日记产品,目前市面上的AI+日记类产品都以预设的、单 agent 系统为主,且不够主动。我们产品在个性化,交互的丰富度上有明显优势。
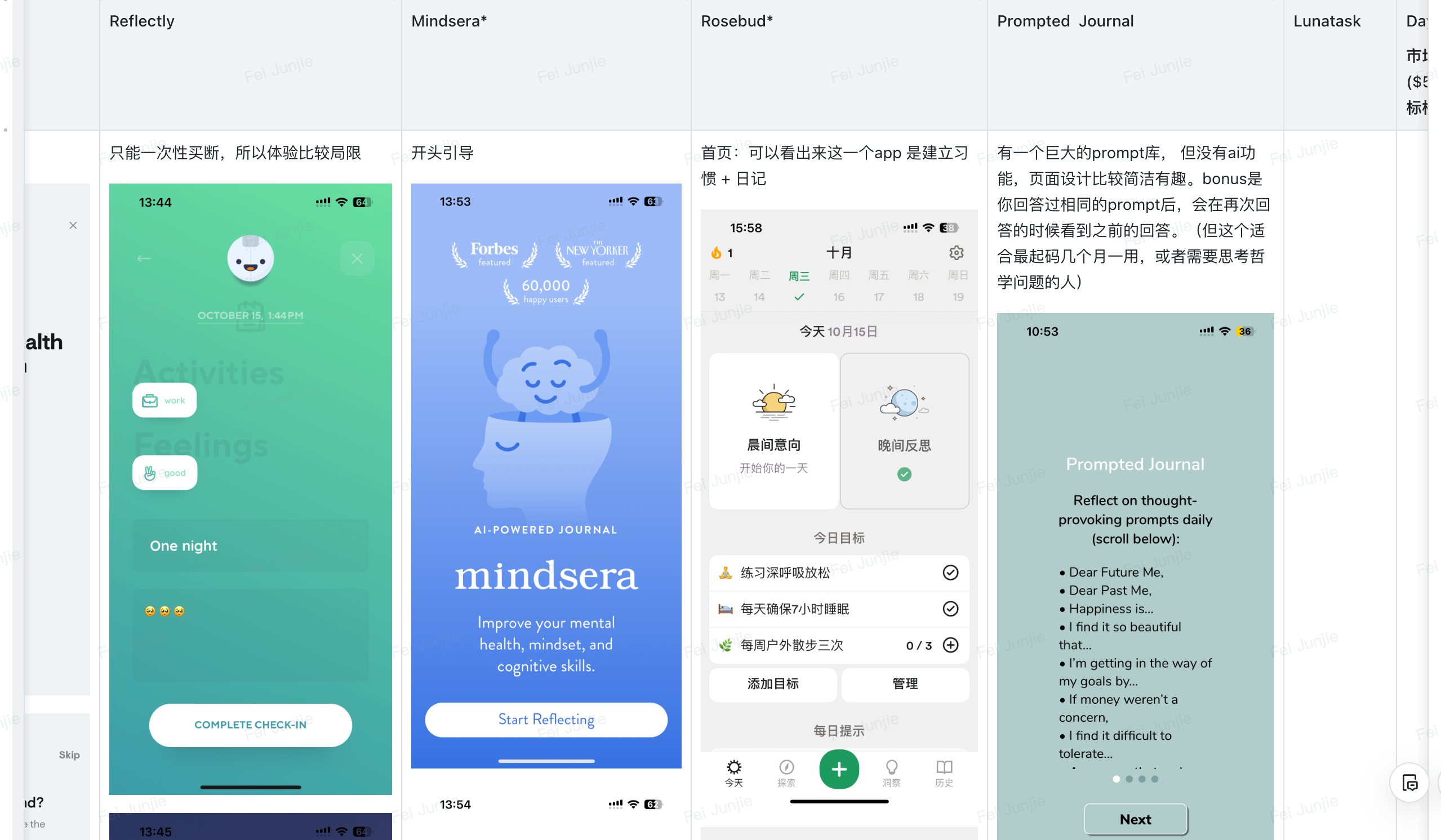
Deliver
见 1.5
软件工程
尽管后端和 AI 智能体方面实力强劲,我们团队成员比较缺乏前端设计的经验,这一路过来,主要是通过 vibe coding 和 AI 斗智斗勇 边做边学,我们相信自己已经做到了高质量的软件的工程,这体现在以下方面:
1. 技术栈现代。我们使用 uv 包管理,docker 部署,我们的 Agent 功能基于自研 Agent 框架 PolyCLI,构建起来快速稳定(代码量极少,native integration with fastapi),且自动具备了丰富的日志功能。
2. 我们记录下了 vibe coding 过程中遇到的各种有趣的案例,不断积累 vibe coding 经验,形成了自己的理解,见仓库 vibe-coding-tutorial
3. 我们先后制作了两款工具来解决 vibe coding 种遇到的问题:为了让不同 code agent 之间方便地交流信息,我们开发了 GitHub - shuxueshuxue/AgentTalk: Minimal HTTP server for AI agents to coordinate across machines and projects。为了方便代码库的 context 管理,实现 Spec-driven development (SDD) ,我们开发了 GitHub - shuxueshuxue/SpexFlow: Node-based workflow for orchestrating codebase context and specifications for AI agents.,并分享到开发者社区,四天时间就获得了 70+ star,15 个fork.
结语
目前我们使用过我们软件的用户 (70人,有反馈者 20 人) 大多对这种交互形式表示新奇,并有约 2/3 的用户表示将持续使用该产品并推荐给他人。如果用这个数据来计算 NPS,将会相当高 - 但这是不准确的,因为更多的(或者说真正有日记习惯的)目标用户还没有看到我们的产品,或许我们目前的 story telling 还不够有吸引力,但我们已经迈出第一步,接下来会持续地去做推广。
AI + 情感陪伴现在已经是热门赛道。以往我们没有一个途径/理由去获取到用户的个人生活、情感经历的相关数据,但现在,此类数据如何去利用,转化为对于个体的知识和对于整体的洞见,成为了一个有待探索的新天地!
个人感想
以下是我作为团队 leader 的一点个人感想。
其实我感觉一开始做的时候我是高估了自己的能力的,主要是前端架构和前后端接口设计方面,我们踩的坑很多包括但不限于:
- PolyCLI 框架有的接口只支持轮询 -> 于是改框架,让其支持同步 API
- 写作界面的数据分散在各个文件里,难以持久化 -> 建立统一的 cell-based 的编辑器数据结构
- 卡组的数据结构设计:如何让用户卡组可以与上游变更同步 -> 使用类似于 github 的 fork 机制
- 编辑器是用 Tiptap 还是 textarea + overlay -> 我们使用后者重新造轮子,但也给了前者永远达不到的自由度
- 前端逻辑重,延迟高 -> 全部创建对应的后端 api,逻辑移到后端
- 服务器带宽小,图片传不动 -> 转换为 jpg 压缩,thumbnail 预览,浏览器缓存
- 依赖复杂,构建麻烦 -> 转换为使用 uv add 而不是 uv pip install,强迫自己使用 docker 部署,终于理清了依赖
- 前端 App.tsx 3k+ 行代码过于臃肿 -> 采用 service+hook+component 的模式进行模块化
- 我们不会前端设计 -> 借鉴现有的产品和大模型的能力把页面做的舒服
- 没有中英文切换 -> 加入 i18n
- 要区分日期,生成每日图片 -> 所有带时间的请求都要带上时区参数
- LLM 给出不符合规范的回复怎么办 -> 拒绝然后重试?那会死循环!我们将它之前犯的错误持久化,显式地放到它的 context 里面
- 语音输入本来想用浏览器自带的服务,发现国内不行 -> 老老实实用后端服务 + websocket 通信实现
- 其余例如域名注册备案,SSL 证书,数据库 schema 更新等等坑实在太多就不一一列举了

可以说,有了最初的想法之后,其余大多数时间都在和“可用性”做斗争。
一路踩坑下来,我的心态也从「想做点很酷的东西」慢慢变成了「踏实把一件小事做好」。以前会更在意技术选型是不是足够“高级”、框架是不是够新,现在更在意的是:用户点开页面要不要等太久、哪一步交互会让人困惑、哪句话的提示能让第一次用的人不害怕。这种从“写代码爽不爽”到“别人用着顺不顺”的视角转换,对我来说是一个挺大的成长。
同时,我也更能体会到:做一个和情绪、生活紧密相关的产品,需要的是耐心和谦卑。我们现在做出来的,也许还远远称不上「有灵性」,但至少是一个诚恳的起点。接下来,我希望我们能花更多时间去和真实用户一起迭代:听他们讲自己的故事,理解他们对陪伴、记忆、理解的真正期待,再一点点把这些抽象的愿望,落实为细致的交互和模型上的改动。
如果有一天,哪怕只有很少一部分人,是因为这个小小的日记本,能更愿意和自己待在一起、更温柔地看待自己的情绪,那我会觉得这一路所有的绕路和返工,都是值得的。